
Outage report: 14-Jan–2019

Starting at 8pm Pacific time yesterday through 3am Pacific time today Althea’s exit servers were down.
This is our first major (longer than a 15 minute) outage since June of 2018. The technical issue exposed is pretty minor, the real feedback here is about a series of failures in our incident recovery procedure.
Primary Causes:
- Incorrect configuration of per process file descriptor limits on the exits
- Recovery failure of some client devices
Failures in incident response procedure:
- Lack of validation of on call procedure
- Lack of secondary emergency recovery contacts
- Incorrect configuration of the service autorecovery on the exits
If any one of these issues had been resolved beforehand this would have been limited to a minor outage.
Primary Causes
Incorrect configuration of per process file descriptor limits on the exits
Getting into the actual technical issue at the root of this. Exit servers forward connections from clients in the Althea network.
Each of these connections takes up what’s called a ‘file descriptor’. While the system wide number of file descriptors had been properly tuned to prevent issues the per-process limit of file descriptors was limited to the default 4096.
Following a momentary networking issue, either within the Clatskine test network or on the larger internet there was a rush of traffic and requests to the Rita exit process on the exit.
Since Rita exit must claim a file descriptor for each connection it has it exceeded 4096 during this period and crashed.
Jan 14 22:55:39 localhost.localdomain rita_exit[26857]: [2019–01–15T03:55:39Z INFO rita_exit::rita_common::network_endpoints] Got Payment from Some(“[fddf:bb15:dd3e:ebf4:2524:550:bb38:50c2]:56648”) for 6360000000 with txid None
Jan 14 22:55:39 localhost.localdomain rita_exit[26857]: thread ‘main’ panicked at ‘called `Result::unwrap()` on an `Err` value: Os { code: 24, kind: Other, message: “No file descriptors available” }’, src/libcore/result.rs:1009:5
Jan 14 22:55:39 localhost.localdomain rita_exit[26857]: note: Run with `RUST_BACKTRACE=1` environment variable to display a backtrace.
Jan 14 22:55:39 localhost.localdomain rita_exit[26857]: Panic in Arbiter thread, shutting down system.
Jan 14 22:55:40 localhost.localdomain systemd[1]: rita-exit.service: main process exited, code=exited, status=101/n/aAs a major network service with potentially hundreds of clients Rita exit should have both been configured to deal with this many connections and have code to prevent too many connections from occurring at the same time in the first place.
That being said if the incident response team was on point this would have been a 5 second fix to avoid downtime.
service rita-exit restart
Recovery failure of some client devices
The Clatskine gateway was also taken down by this incident and failed to automatically recover itself.
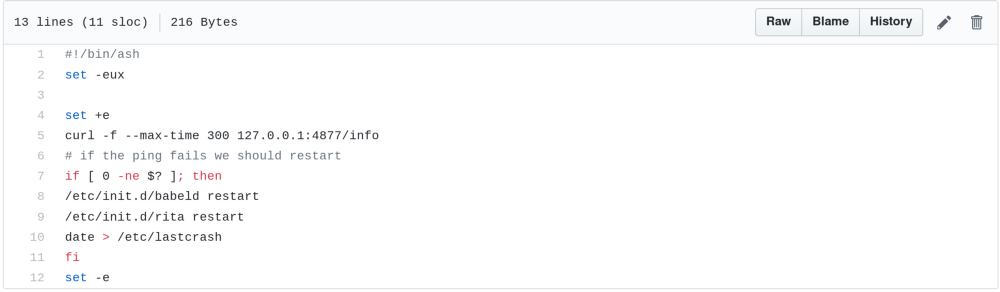
This can be attributed to the watchdog script checking only the liveness of Rita and not if Babel actually has any routes.
It will be revised to more carefully check that Babel is functioning correctly and not simply limping along in a zombie state.
This was the most non-trivial failure for this incident, as it had to be recovered on site.
Remote access will be setup for the maintainer of the gateway to make this process easier in addition to better automated recovery.
Failures in incident response
Moving onto issues with the recovery response. Recovery for this incident should have ideally taken less than 15 minutes and as few as 5 minutes. Instead it took over 6 hours.
Lack of validation of on call procedure
Late last year the Android phone of the primary on call contact received an update to Android Oreo.
During this update the Do-No-Disturb feature had it’s behavior changed and configuration reset.
Instead of defaulting to a higher ringer volume for priority calls the call was allowed through but using the system ringer volume, resulting in a vibrating phone that did not wake the on call contact.
Lack of secondary emergency recovery contacts
Emergency recovery documentation was in place and accessible. But the technical personnel responding to the issue did not have ssh access to the primary exit server.
A ssh key was requested at install time, but not followed up on. Resulting in only two people having access to the production system at the time of the incident.
Of these two only one was on call and as previously described the on call procedure failed.
Incorrect configuration of the service autorecovery on the exits
Due to the transient nature of this issue simply restarting the Rita exit service on the exit would have sufficed for restoring the system to functionality.
Anyone with access to the system could have done this trivially. The service itself could have also been configured to attempt a reboot upon failure.
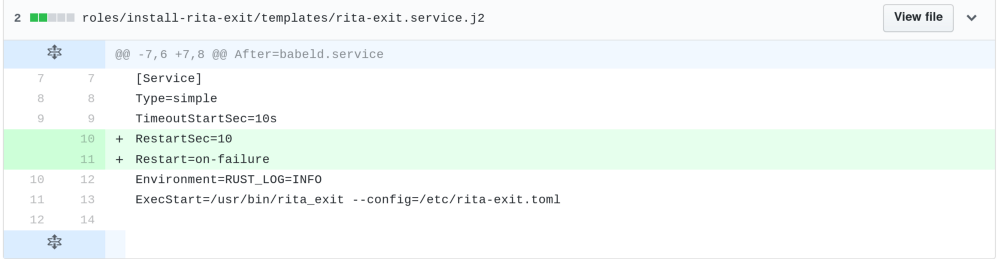
By adding these two lines to the service template the exit would have been automatically recovered.
All services are now back online, we hope to have all issues in this post mitigated by the end of this week.